“Boston House Prices” dataseti üzərindən maşın öyrənmə alqoritminin qurulması
Mündəricat:
· Giriş
· Dataset haqqında
· Dataset ümumi baxış
· İstifadə ediləcək vasitələr haqqında
· Data emalı (Data Preprocessing)
· Data analizi (EDA)
· Modelin qurulması (Model Building)
· Modelin performansı (Model Performances)
· Proqnoz və Yekun Hesab
Giriş
Hər bir dataset bir dərin mədəndir. Daha dərindən analiz etdiyimizdə mədənin bizə qoyduğu qiymətli filizləri tapa bilərik.
B u gün evin yeri, qiyməti və s. kimi digər məlumatlardan ibarət dataset üzərində işləyəcəyik. Bu tərz dataset üzərində işləyərkən əsas məqsədimiz hansı sütunların bizim üçün önəmli olduğunu müəyyən etməkdir. Bugünkü əsas məqsədimiz dəyişənlərə (column variables)əsaslanaraq bizə evin qiyməti haqqında yaxşı proqnoz verə biləcək model yaratmaqdır.
Dataset haqqında
Mənzil qiymətləri iqtisadiyyatın mühüm əksidir və mənzil qiymət diapazonları həm alıcılar, həm də satıcılar üçün böyük maraq doğurur. Bu proyektdə yaşayış evlərinin bir çox aspektlərini əhatə edən dəyişənlər (features) nəzərə alınmaqla ev qiymətləri proqnozlaşdıracayıq. Bu layihənin məqsədi- dəyişənləri nəzərə alınmaqla, evin qiymətini dəqiq qiymətləndirə bilən reqressiya modelini (Regression model) yaratmaqdır.
Problemi anlamaq

Mənzil qiymətləri həm alıcılar, həm də satıcılar üçün böyük maraq doğurur. Bir ev alıcısından xəyal etdiyi evi təsvir etməsini xahiş etsək yəqin ki, zirzəmi tavanının hündürlüyündən və ya magistral yola yaxınlığından başlamayacaq. Lakin bu dataset sübut edir ki, qiymət danışıqlarına otaq sayı evin genişliyi vs. kimi primitiv xüsusiyyətlərdən başqa daha fərqli xüsusiyyətlər çox təsir edir.
Datasetə ümumi baxış (Data Overview)
Dataseti ilkin olaraq çalışdırdığımızda görə bilərik ki, bizə sütun adları (column variable) verilməyib:⬇

༼つಠ益ಠ ༽つ ─=≡ΣO)) Specialis Revelio! … Sehirli sözlərdən sonra datasetimiz aşğıdakı hala gətirilir, yəni ona sütun adları veririk.(Sehirli sözlərimiz (kodlarımız) haqqında irəli hissədə danışacayıq :)) Sütun adlarını Kaggle saytında “Context” bölmündən götürürük. ⬇
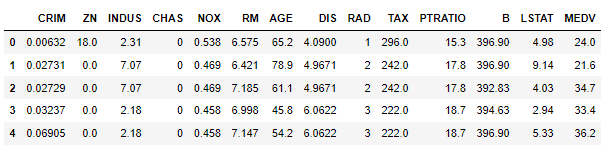
- CRIM — Per capita crime rate by town Şəhərlər üzrə adambaşına düşən cinayət nisbəti. CRIM Boston metropoliteninin müxtəlif məhəllələrində məişət rifahı üçün qəbul edilən təhlükəni ölçdüyünə görə (cinayət nisbətlərinin insanların təhlükə qavrayışları ilə mütənasib olduğunu nəzərə alsaq), ev dəyərlərinə mənfi təsir göstərməlidir.
- ZN — The proportion of residential land zoned for lots over 25,000 sq. ft 25.000 kvadrat futdan böyük ərazilərdə rayonlaşdırılan şəhərin yaşayış sahəsinin payı. ZS-nin mənzil qiymətləri ilə müsbət korrelyasiya olmasını gözləyirik, çünki bu tip rayonlaşdırma kiçik evlərin tikintisini məhdudlaşdırır, həmçinin sakinlərin rifahını, sosial təbəqəsini də əks etdirir.
- INDUS — The proportion of non-retail business acres per town, (1 akr = 4046,86 kv.m). Şəhər üzrə qeyri-pərakəndə biznes sahələrinin nisbəti INDUS sənaye səs-küyü, sıx trafik və xoşagəlməz vizual xarici təsirlər üçün proksi kimi çıxış edir və buna görə də yaşayış qiymətlərinə mənfi təsir göstərməsi gözlənilir.
- CHAS — Charles River dummy variable (1 if tract bounds river; 0 otherwise) Charles çayı dummy dəyişəni: Əgər bölgə Charles çayını əhatə edirsə = 1; əks halda =0. CHAS çay kənarında yerləşmə imkanlarını əhatə edir və buna görə də əmsal (coefficient) müsbət olmalısı gözlənilir.
- NOX —Nitric oxides concentration (parts per 10 million) Azot oksidi konsentrasiyası ppm’lə (ppm = ‘‘parts per million’’, illik orta konsentrasiyası hər 10 milyonda).
- RM — The average number of rooms per dwelling. Yaşayış məntəqəsinə düşən otaqların orta sayı. RM genişliyi və bir növ mənzilin ölçüsünü ifadə edir. Bu, mənzil dəyəri ilə müsbət əlaqəlidir. RM² formasının xətti və ya loqarifmik formalardan daha yaxşı uyğunluq təmin etdiyi aşkar edilmişdir.
- AGE — The proportion of owner-occupied units built prior to 1940. 1940-cı ildən əvvəl tikilmiş mülkiyyət bölmələrinin nisbəti. Vahid yaşı çox vaxt tikinti keyfiyyəti ilə bağlıdır.
- DIS — Weighted distances to five Boston employment centres. Boston bölgəsindəki beş məşğulluq mərkəzinə qədər məsafə. Şəhər urban renta gradientinin ənənəvi nəzəriyyələrinə görə, məşğulluq mərkəzlərinin yaxınlığında mənzil qiymətləri daha yüksək olmalıdır. DIS loqarifm şəklində daxil edilir; gözlənilən işarə mənfidir.
- RAD — Index of accessibility to radial highways. Radial magistral yollara əlçatanlıq indeksi. Magistral yola çıxış indeksi şəhər əsasında hesablanmışdır.
- TAX — full-value property-tax rate per $10,000. Hər 10.000$ düşən tam dəyərli əmlak vergisi nisbəti. İctimai xidmətlərin dəyərini ölçür.
- PTRATIO — Pupil-teacher ratio by town. Məktəb dairəsi üzrə şagird-müəllim nisbəti. Hər bir şəhərdə ictimai sektorun faydalarını ölçür. Təhsilin şagird-müəllim nisbətinin məktəb keyfiyyəti ilə əlaqəsi tam aydın deyil, lakin aşağı nisbət hər bir şagirdə daha çox fərdi diqqət göstərməli olduğunu bildirir.
- B — 1000(Bk — 0.63)² where Bk is the proportion of blacks by town. Qaradərili əhalinin nisbəti. Əgər Qaradərililər Ağdərililər tərəfindən arzuolunmaz qonşular kimi qəbul edilərsə, B-nin aşağı və orta səviyyələrində artım mənzil dəyərinə mənfi təsir göstərməlidir. Buna baxmayaraq bazar ayrı-seçkiliyi bunu ifadə edirki, mənzil dəyərləri B-nin çox yüksək səviyyələrində daha yüksəkdir. Buna görə də, qonşuluqdakı Qaradərili nisbəti ilə mənzil dəyərləri arasında parabolik əlaqə gözlənilir.
- LSTAT — lower status of the population %. Aşağı statuslu əhalinin nisbəti faizlə
- MEDV — Median value of owner-occupied homes in $1000’s Sahibkarın yaşadığı evlərin orta dəyəri 1000 $-la . MEDV bizim (target variable) hədəf dəyişənimizdir.
Dasaset haqqında məqaləyə bu linkdən daxil ola bilərsiz.
İstifadə ediləcək vasitələr haqqında

Bu layihənin əsas məqsədi bəzi reqressiya üsulları(regression techniques) və alqoritmlərindən istifadə edərək dəyişənlərə əsaslanaraq ev qiymətlərini proqnozlaşdırmaqdır.
İstifadə ediləcək programlaşdırma dili:
Python. Kodu yazmaq üçün Anaconda Navigator və xüsusilə Jupyter notebook istifadə edəcəyik.
İstifadə ediləcək algorithmlər:
1. Linear Regression
2. Random Forest Regressor
İstifadə ediləcək maşın öyrənmə vasitələri (machine learning packages):
Numpy, Pandas, Scikitlearn, Seaborn, Matplotlib, Scipy
Data emalı (Data Preprocessing)
Data üzərində ön işləmə Maşın Öyrənməsində ayrılmaz bir addımdır, çünki dataların keyfiyyəti və ondan əldə edilə bilən faydalı məlumat modelimizin öyrənmə qabiliyyətinə birbaşa təsir göstərir; buna görə də, datanı modelimizə daxil etməzdən əvvəl data üzərində ön işləmə etməyimiz son dərəcə vacibdir. Aşağıdakı addımları bir-bir edəcəyik:
1.Kitabxanaların daxil edilməsi
2.Dataseti yükləmək
3.Missing values üzərində işləmək
1.Kitabxanaları daxil etmək
Python Kitabxanaları sıfırdan kod yazmaq ehtiyacını aradan qaldıran faydalı funksiyalar toplusudur. Python kitabxanaları maşın öyrənməsi, data elmi, datanın vizuallaşdırılması, görüntü və dataların manipulyasiya tətbiqləri və s. inkişaf etdirilməsində mühüm rol oynayır. Aşağıda qeyd edilən bütün kitabxanalar open-source’dur.
#Importing some libraries
from sklearn import preprocessing
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inlineimport seaborn as sns
from scipy import statsimport warningsfrom sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
Sklearn.preprocessing paketi müxtəlif funksiyalarla bizi təmin edir, hansıkı bular xam feature’ları maşın öyrənmə modelləri üçün daha uyğun olan formaya gətirməyə kömək edir.
Sklearn.linear_model sklearn kitabxanasının sinfidir, xətti modellərlə(regression models) maşın öyrənməsini həyata keçirmək üçün müxtəlif funksiyaları özündə cəmləyir.
Sklearn.metrics Sklearn.metrics modulu classification performance ölçmək üçün loss, score,utility və bəzi funksiyaları həyata keçirir.
Pandas data təhlili (data analysis) üçün Python kitabxanasıdır.Pandas iki əsas Python kitabxanasının üzərində qurulub — verilənlərin vizuallaşdırılması üçün matplotlib və riyazi əməliyyatlar üçün NumPy. Burda as pd yazaraq pandas sözünü qısaldırıq.
Numpy Python-a array’lər və matrislərlə effektli hesablamaları təmin edən güclü data strukturları əlavə edir və bu array’lər və matrislər üzərində işləyən ali riyazi funksiyaların böyük kitabxanasını özündə birləşdirmişdir.
matplotlib.pyplot as plt Matlpotlib Python və Numpy üçün data vizuallaşdırma və qrafiki tərtibat kitabxanasıdır.
%matplotlib inline IPython-da sehrli funksiyadır. %matplotlib inline xətti plot outputları göstərəcək və notebookda onları saxlayacaq.
Seaborn Matplotlib üzərində qurulmuş vizuallaşdırma üçün istifadə edilən kitabxanalardandır.
Scipy Python-da SciPy riyazi, elmi, mühəndislik və texniki problemlərin həlli üçün istifadə olunan kitabxanadır.
Warnings Mühüm hesab edilməyən qeyri-adi hallarda (exception) xəbərdarlıq mesajı göstərir.
2.Dataseti yükləmək
Gəlin sehirli kodlarımızdan danışaq :)
CSV faylarını oxumaq üçün read_csv() funksiyasından istifadə edirik. read_csv() funksiyasının parametrlərinə əsasən faylımız harda yerləşdiyini göstərən dəyişənə ehtiyacımız var. Parametrlərə nəzər salmaq üçün Jupyter notebookda shift+tab keylərinə basmalıyıq.
filepath = "C:\\Users\\User\\Desktop\\housing.csv"
boston_df = pd.read_csv(filepath)Output:
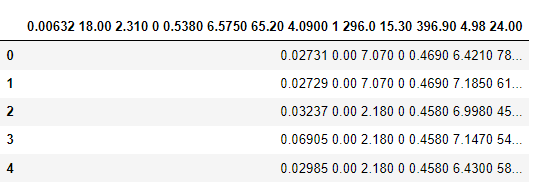
Əvvəldə qeyd etdiyim kimi dataseti ilk yüklədiyimizdə görürük ki, sütun adları verilməmişdir. Bunun üçün ilk öncə column_names adlı dəyişən yaradırıq. Bura datasetin izahı bölmündə qeyd edilmiş sütun adlarını list formasında yazırıq. (Scikit-learn datasetindən istifadə ediriksə,boston_df.feature_names yazmaqla column variables əldə edə bilərik).
filepath = "C:\\Users\\User\\Desktop\\housing.csv"column_names = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV']
boston_df = pd.read_csv(filepath, header = None, delimiter=r"\s+", names = column_names)
read_csv() funksiyasının digər parmetrlərindən istifadə etdik. İlk sətirimizdə sütun adları olmadığı üçün header = None yazaraq bunu pandasa bildiririk. delimiter =r”\s+” (‘delimiter’-‘sep’ parametrinin digər qoşma adıdır)delimiterləri data elementləri arasında ayırıcı kimi düşünə bilərik. delimiter parametri hansı ayırıcının istifadə edildiyini, data elementlərinin CSV faylımızda necə ayrıldığını bildirir. \s+ burda bir və ya bir neçə boşluq buraxılmasını ifadə edir. names parametri sütun adlarını təyin etmək üçün istifadə olunur.
3.Missing values üzərində işləmək
Gəlin biraz daha sehr edək və heç bir missing value olmadığından əmin olaq:
(∩`-´)⊃━☆゚.*・np.shape() 。゚ ☆゚.*・ len() 。゚size ☆゚.*・columns。゚
print(np.shape(boston_df))
print("Number of columns:", len(boston_df.columns))
print('number of rows:', len(boston_df))
print('number of elements:', boston_df.size)(506, 14)
Number of columns: 14
number of rows: 506
number of elements: 7084
np.shape() NumPyda, shape funksiyasından istifadə edirik hansı ki tuple içində bizə ölçü qaytarır. Burda 506 sətir, 14 sütunların sayıdır.Verilmiş Dataframe-in column label qaytarmaq üçün DataFrame.columns atributundan istifadə edirik.
(∩`-´)⊃━☆゚.*・。゚ info() ☆゚.*・。゚
boston_df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 506 entries, 0 to 505
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 CRIM 506 non-null float64
1 ZN 506 non-null float64
2 INDUS 506 non-null float64
3 CHAS 506 non-null int64
4 NOX 506 non-null float64
5 RM 506 non-null float64
6 AGE 506 non-null float64
7 DIS 506 non-null float64
8 RAD 506 non-null int64
9 TAX 506 non-null float64
10 PTRATIO 506 non-null float64
11 B 506 non-null float64
12 LSTAT 506 non-null float64
13 MEDV 506 non-null float64
dtypes: float64(12), int64(2)
memory usage: 55.5 KB
Pandas dataframe.info() funksiyası dataframe haqqında qısa xülasə (summary) əldə etmək üçün istifadə olunur. Burda data tipləri, yaddaş istifadəsi və non-null dəyərlərin sayını görə bilərik. Bizdə bütün qiymətlər 506-dır. Null value burda yoxdur.
(∩`-´)⊃━☆゚.*・。゚ duplicated() ☆゚.*・。゚
duplicate_rows_df = boston_df[boston_df.duplicated()]
print('number of duplicate rows:', duplicate_rows_df.shape)number of duplicate rows: (0, 14)
dublicaded() yalnız dublikat dəyərləri təhlil etməyə kömək edir. Boolean (True, False) tipli dəyər ələd edirik, dublikat dəyərlər üçün False qaytarır.
(∩`-´)⊃━☆゚.*・。゚isnull() 。゚ ☆゚.*・sum() ☆゚.*・。゚
missing_data =boston_df.isnull().sum()
missing_data
CRIM 0
ZN 0
INDUS 0
CHAS 0
NOX 0
RM 0
AGE 0
DIS 0
RAD 0
TAX 0
PTRATIO 0
B 0
LSTAT 0
MEDV 0
dtype: int64isnull().sum() missing dataların sayını müəyyən edir
(∩`-´)⊃━☆゚.*・columns.values.tolist()。゚☆゚.*・。゚ 。゚ ☆゚.*value_counts()・ 。゚ ☆゚.*・ 。゚ ☆゚.*・
for column in missing_data.columns.values.tolist():
print(column)
print (missing_data[column].value_counts())
print("")
CRIM
False 506
Name: CRIM, dtype: int64
ZN
False 506
Name: ZN, dtype: int64
INDUS
False 506
Name: INDUS, dtype: int64
CHAS
False 506
Name: CHAS, dtype: int64
NOX
False 506
Name: NOX, dtype: int64
RM
False 506
Name: RM, dtype: int64
AGE
False 506
Name: AGE, dtype: int64
DIS
False 506
Name: DIS, dtype: int64
RAD
False 506
Name: RAD, dtype: int64
TAX
False 506
Name: TAX, dtype: int64
PTRATIO
False 506
Name: PTRATIO, dtype: int64
B
False 506
Name: B, dtype: int64
LSTAT
False 506
Name: LSTAT, dtype: int64
MEDV
False 506
Name: MEDV, dtype: int64Biz DataFrame.columns.values.tolist() metodu ilə Pandas DataFrame-nin sütun adlarını list şəklində əldə edə bilərik. value_counts() funksiyası unikal dəyərlərin sayını göstərən obyekti qaytarır.
Missing datanın olub olmadığını müəyyən etmək üçün əksər istifadə olunan kodları yazdıq. Boston datasetimizdə heç bir missing value yoxudur. Missing values və ya missing data adətən Nan ,null və ya None olaraq datasetdə göstərilir. (Real həyatdan götürülmüş datasetlərin içində missing dataların olmaması biraz qeyri-realdır)
Data analizi (Exploratory Data Analysis,EDA)
Exploratory Data Analysis (EDA) çox vaxt vizuallaşdırma üsulları ilə dataset-in əsas xüsusiyyətlərini ümumiləşdirir. Datanın bizə modelləmə və ya hyothesis testing-in üzərində nə deyə biləcəyini araşdırırıq.
Unikal dəyərlərin tapılması və hansı dəyərlərin kateqorik (categorical) və ya kəsilməz (continuous) olduğunu müəyyən etmək üçün Pandasın nunique() funksiyasından istifadə edirik. Həmçinin, unikal dəyərlərin sayı < 20-dirsə dəyişən kateqorik hesab edilə bilər.
boston_df.nunique()CRIM 504
ZN 26
INDUS 76
CHAS 2
NOX 81
RM 446
AGE 356
DIS 412
RAD 9
TAX 66
PTRATIO 46
B 357
LSTAT 455
MEDV 229
dtype: int64
Yuxarıdakı araşdırmalara əsaslanaraq, indi hər bir sütunla bağlı müşahidələrinizi qeyd edərək məlumatların sadə hesabatını yarada bilərik.
- CRIM — Kəsilməz.
- ZN —Kəsilməz .
- INDUS — Kəsilməz.
- CHAS —Kateqorik.
- NOX — Kəsilməz.
- RM — Kəsilməz.
- AGE — Kəsilməz.
- DIS — Kəsilməz.
- RAD — Kateqorik.
- TAX — Kəsilməz.
- PTRATIO — Kəsilməz.
- B — Kəsilməz.
- LSTAT — Kəsilməz.
- MEDV — Kəsilməz. Hədəf dəyişən (Target Variable)
boston_df.describe(include='all')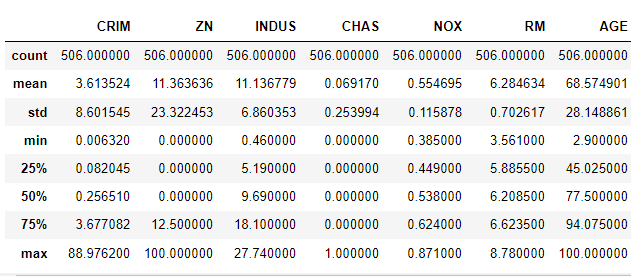
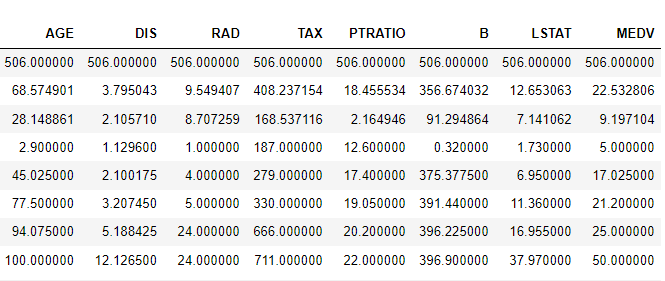
ZN: 25, 50 faizləri üçün nəticə 0-dır. CHAS: burda da 25, 50 və 75-ci faizlər üçün nəticə 0-dır. Birinci fərziyyə odur ki, bu sütunlar MEDV-nin proqnozlaşdırılması kimi reqressiya tapşırığında faydalı olmaya bilər.
Bar plot-dan istifadə edərək bütün kateqorik dəyişənlərin paylanmasını (distribution) vizuallaşdıracayıq.
sns.set_style('whitegrid')
sns.countplot(x='CHAS',data=boston_df)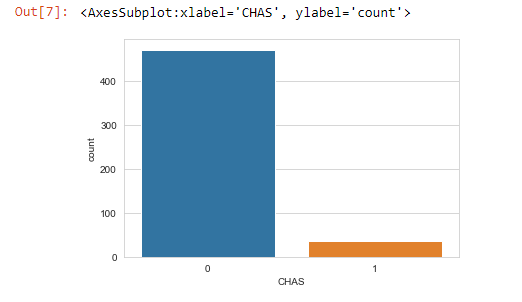
sns.set_style('whitegrid')
sns.countplot(x= 'RAD',data=boston_df,palette='RdBu_r')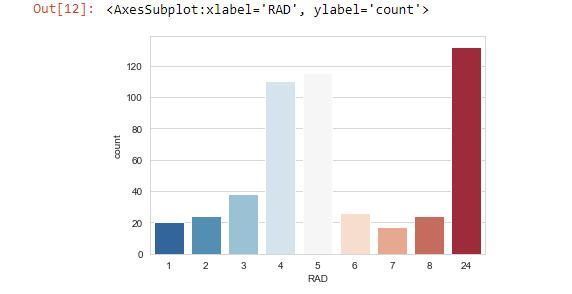
Bar qraflarda Y oxu hər kateqoriyanın tezliyini X oxu isə kateqoriyanın adını göstərir. İdeal bar qrafda hər kateqoriya müqayisə edilə biləcək qədər tezliyə sahib olur. Bu datasetdə Ml alqoritmin öyrənməsi üçün hər kateqoriyada kifayət qədər sətir vardır. Əgər bir sütun əyri paylanılıbsa (skewed distribution) və burada bir dominant bar varsa, bu növ sütunlar machine learning-də faydalı olmaya bilər. Bunu korrelasiya analizi bölmündə yoxlayacayıq.
Bizim datasetimizdə CHAS sütununda əyim vardır(skewed). Burada sadəcə bir bar dominantdır, digəri isə çox az sətirə malikdir. Belə sütunlar adətən hədəf dəyişənlə korrelyasiyası olmur, çünki öyrənmək üçün kifayət qədər data yoxdur və alqoritm burda hər hansı bir qayda tapa bilmir.
Hədəf dəyişəninin paylanması :
Hədəf dəyişənin paylanması çox əyri olarsa, proqnozlaşdırıcı modelləşdirmə mümkün olmayacaq. Zəng əyrisi arzuolunandır, lakin bir az müsbət və ya mənfi əyilmə də yaxşıdır. Reqressiyanı həyata keçirərkən histogramın zəng əyrisinə bənzədiyindən və ya onun bənzər bir versiyası olduğundan əmin olun. Digər halda bu Maşın öyrənmə alqoritminin öyrənmə qabiliyyətinə təsir edəcək.
sns.set(rc={'figure.figsize':(11,8)})
sns.distplot(boston_df['MEDV'])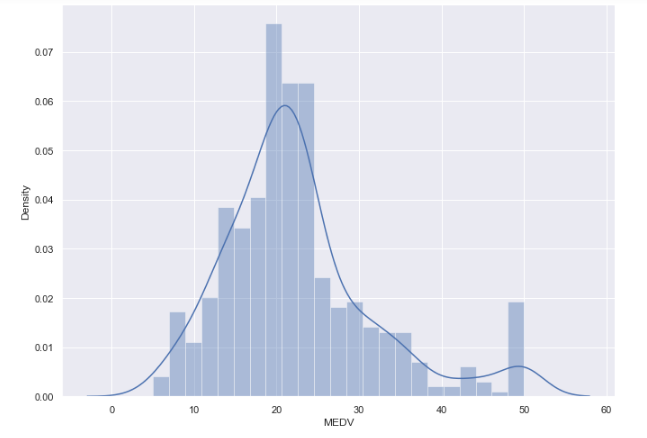
Hədəf dəyişənin paylanması yaxşıdır və az outlier müşahidə olunur. Burada hər tip dəyərin öyrənməsi üçün kifayət qədər sətir vardır.
Histogram üçün ideal nəticə zəng əyrisi (bell curve) və ya bir qədər əyilmiş zəng əyrisidir (slightly skewed bell curve). Əgər çox əyrilik varsa, bunun səbəbi kənar dəyərlər (outliers) olacaqdır. Kənar dəyərlər verilənlərin əksəriyyətindən uzaq olan ekstremal dəyərlərdir. Onları histoqramda quyruq kimi görə bilərsiniz. Outliers ehtiva edən sütunların üzərində işləmək və onları yenidən yoxlamaq lazımdır. Əgər problem bununla həll olunmasa, həmin sütun yararsız hesab edilə bilər.
fig, ax = plt.subplots(ncols=7, nrows=2, figsize=(20, 10))
warnings.filterwarnings("ignore")
index = 0
ax = ax.flatten()for col, value in boston_df.items():
sns.distplot(value, ax=ax[index])
index += 1
plt.tight_layout(pad=0.5, w_pad=0.7, h_pad=5.0)
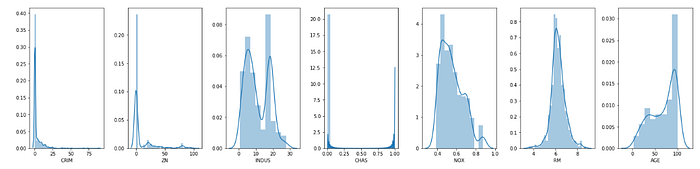
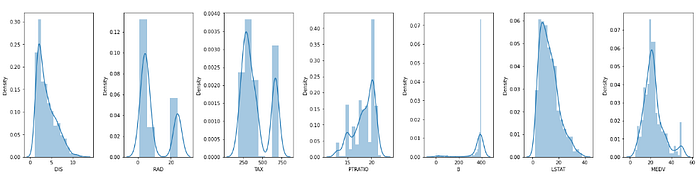
Yuxarıdakı histogram hər bir kəsilməz dəyişən üçün datanın paylanmasını göstərir. X oxu dəyişənlərin diapazonunu, Y oxu isə həmin diapazondakı dəyişənlərin sıxlığını göstərir.
Digər sütunlarda CHAS (diskret dəyişən ) istisna olmaqla, sütunların normal və ya bimodel paylanması var.
Datasetimizdə kənar göstəriciləri analiz etmək üçün boxplots tərtib edəcəyik.
fig, axs = plt.subplots(ncols=7, nrows=2, figsize=(20, 10))
index = 0
axs = axs.flatten()
for k,v in boston_df.items():
sns.boxplot(y=k, data=boston_df, ax=axs[index])
index += 1
plt.tight_layout(pad=0.4, w_pad=0.5, h_pad=5.0)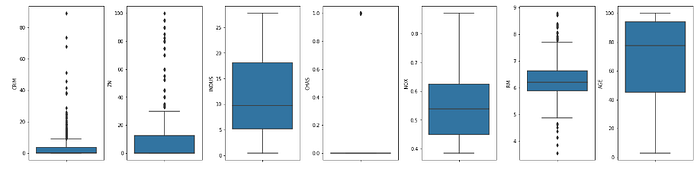
CRIM, ZN, RM, B sütunların kənar göstəriciləri çox (outliers) görünür. Hər sütundakı kənar göstəricilərin faizlərinə baxaq.
for k, v in boston_df.items():
q1 = v.quantile(0.25)
q3 = v.quantile(0.75)
irq = q3 - q1
v_col = v[(v <= q1 - 1.5 * irq) | (v >= q3 + 1.5 * irq)]
perc = np.shape(v_col)[0] * 100.0 / np.shape(boston_df)[0]
print("%s sütunun outlier faizi = %.2f%%" % (k, perc))
Dəyişən ‘CRIM’, ‘B’, ‘ZN’ modelimizin dəqiqliyinə mənfi təsir göstərə biləcək qədər yüksək faiz kənar göstəricilərə malikdir.
Bu problemi həll etmək üçün ilk həmin sütunları bütünlüklə silə bilərik və ya mean, median kimi bəzi yanaşmalarla əvəz edə bilərik. Lakin bütün kənar göstəricilərin olduğu sütunları silmək yaxşı fikir olmaya bilər, çünki modelimizi öyrətmək üçün kənar göstəricilərin daha yüksək olmasına görə çox az müşahidələrlə (observations) qalacağıq, həmçinin kənar göstəricilərin belə böyük faizini hansısa yanaşma ilə əvəz etsək (mean, median … və s.) o zaman daha az dəqiq və ya (biased) modellə nəticələnə bilər.
Aşağıda dəyişənlər arasında xətti əlaqələri göstərən korrelyasiya matrisi yaradılmışdır. Korrelyasiya matrisi pandas kitabxanasından corr funksiyasından istifadə etməklə yaradılmışdır. Korrelyasiya matrisini çəkmək üçün seaborn kitabxanasının heatmap funksiyasından istifadə edirik. Korrelyasiya əmsalı -1 ilə 1 arasında dəyişir. Əgər dəyər 1-ə yaxındırsa, bu, iki dəyişən arasında güclü müsbət korrelyasiya olduğunu bildirir. -1-ə yaxın olduqda, dəyişənlər güclü mənfi korrelyasiyaya malikdirlər.
Pearson korrelyasiya əmsalı iki dəyişənin kovariasiyasıdır, onların standart sapmalarının (standart deviation) hasilinə bölünür.

x̄- müstəqil dəyişənin orta qiyməti , x- müstəqil dəyişən, y- asılı dəyişən, ȳ — asılı dəyişənin orta qiyməti.
plt.figure(figsize=(16, 6))
heatmap = sns.heatmap(boston_df.corr(), vmin=-1, vmax=1, annot=True, cmap='BrBG')
heatmap.set_title('Correlation Heatmap', fontdict={'fontsize':18}, pad=12);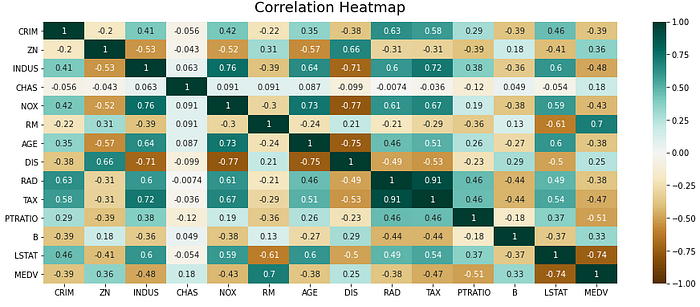
Bu korrelyasiya əsasında MEDV sütununa uyğun sıralayırıq.
medv_value = correlation.iloc[0:13,13].to_numpy()
index_name = ['CRIM', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV', 'ZN']
medv_df = pd.DataFrame(corr_medv_value, columns=['CORR_MEDV'], index=corr_index_name).sort_values(by='CORR_MEDV')
print(medv_df)
medv_df.plot(kind='bar')
plt.xlabel('Features')
plt.ylabel('Korrelyasiya əmsalı')
plt.title('Hər bir feature üçün MEDV ilə korrelyasiya əmsalı')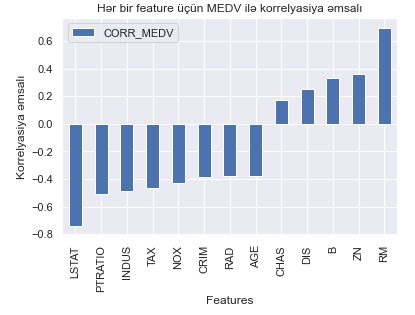
Mənfi korrelyasiya üçün LSTAT və PTRATIO, müsbət korrelyasiya üçün ZN və RM-in yüksək göstəricisi müşahidə olunur. LSTAT mənfi korrelyasiya üçün ən yüksək korrelyasiyadır və PTRATIO ikinci olaraq onu izləyir. Mənfi korrelyasiya bu featureların MEDV ilə tərs mütənasib olduğunu göstərir. Bu, nə qədər yüksək LSTAT və PTRATIO olarsa, o qədər də aşağı MEDV deməkdir. Lakin, LSTAT PTRATIO-dan daha çox MEDV-a təsir edir. Digər tərəfdən, RM müsbət korrelyasiya üçün ən yüksək göstəricidir və ZN onu ardıcıl olaraq izləyir. Müsbət korrelyasiya bu featureların MEDV ilə birbaşa mütənasib olduğunu göstərir. Bu o deməkdir ki, RM və ZN nə qədər yüksək olsa, MEDV bir o qədər yüksəkdir. Bununla belə, RM hədəf dəyişən MEDV-a daha çox təsir edir. Həmçinin burada CHAS MEDV-a çox da əhəmiyyətli təsir göstərmir.
Xətti reqressiya modeli üçün dəyişənlərin seçilməsində vacib məqam multikolinearlığı (multicolinearity) yoxlamaqdır. RAD, TAX dəyişənləri 0,91 nisbətinə malikdir. Bu dəyişənlər arasında güclü əlaqə var. Modeli öyrətmək üçün hər iki dəyişəni birlikdə seçə bilmərik. Həmçinin DIS və NOX 0,77 qiymətlə yüksək korrelyasiyaya malikdir.
# Korrelyasiya matrisinin hesablanması
continuous_col=['MEDV','CRIM', 'ZN', 'INDUS', 'NOX', 'RM', 'AGE', 'DIS', 'TAX', 'PTRATIO', 'B', 'LSTAT']# Korrelyasiya matrisinin yaradılması
correlation_data =boston_df[ContinuousCols].corr()correlation_data['MEDV'][abs(correlation_data['MEDV']) > 0.5 ]MEDV 1.000000
RM 0.695360
PTRATIO -0.507787
LSTAT -0.737663
Name: MEDV, dtype: float64
‘LSTAT’, ‘PTRATIO’, ‘RM’ sütunlarının MEDV ilə 0,5-dən yuxarı korrelyasiya nəticəsi vardı. Həmin dəyişənləri proqnozlaşdırıcı kimi istifadə etmək olar.
Bu sütunların MEDV-lə əlaqəsini təsvir etmək üçün scatterplot matrisi yaradaq. Scatterplot-a reqressiya xətti əlavə etmək xətti trendi görmək üçün əla yoldur.
Biz scatterplot yaratmaq üçün Seaborn-un regplot() funksiyasından istifadə edə bilərik. Və regplot() standart olaraq müəyyən intervalı ilə reqressiya xətti əlavə edir. Burada görünən bir tendensiya olub-olmadığını görməyə çalışacayıq. Üç ssenari ola bilər:
Artan Trend: Bu o deməkdir ki, hər iki dəyişən müsbət korrelyasiyalıdır. Daha sadə dillə desək, onlar bir-biri ilə düz mütənasibdir, əgər bir dəyər artarsa, digəri də artır. Bu ML üçün yaxşıdır!
Trendin azalması: Bu, hər iki dəyişənin mənfi korrelyasiya olduğunu bildirir. Daha sadə dillə desək, onlar bir-birinə tərs mütənasibdir, əgər bir dəyər artarsa, digəri azalır. Bu ML üçün də yaxşıdır!
Trend yoxdur: Siz heç bir aydın artan və ya azalan tendensiya görə bilmirik. Bu o deməkdir ki, dəyişənlər arasında korrelyasiya yoxdur. Beləliklə, proqnozlaşdırıcı ML üçün istifadə edilə bilməz.
Bu diaqrama əsasən, proqnozlaşdırıcının faydalı olub-olmayacağı barədə yaxşı bir fikir əldə edə bilərik və əvvəlcə etdiyimiz korrelyasiya analizi ilə bunu təsdiq etmiş oluruq.
column_sels = ['LSTAT', 'PTRATIO', 'RM']
x = boston_df.loc[:,column_sels]
y = boston_df['MEDV']
fig, axs = plt.subplots(ncols=3, nrows=1, figsize=(15,3))
index = 0
axs = axs.flatten()
for i, k in enumerate(column_sels):
sns.regplot(y=y, x=x[k], ax=axs[i])
plt.tight_layout(pad=0.4, w_pad=0.5, h_pad=5.0)
LSTAT: Aşağı statuslu əhali ilə qiymət arasında güclü mənfi korrelyasiya görə bilərik. Aşağı statusun əhalisi qiymətin azalması/artması ilə artır/azalır. Aşağı statuslu əhalinin üstünlük təşkil etdiyi bölgədəki sosial mühit gənc uşaqlar üçün əlverişli olmaya bilər. O, həmçinin Yuxarı statuslu vətəndaşların üstünlük təşkil etdiyi ərazi ilə müqayisədə nisbətən təhlükəli ola bilər. Beləliklə, daha çox Aşağı statuslu vətəndaşların olduğu bir ərazi tələbi azaldacaq, buna görə də qiymətlər aşağı düşəcəkdir.
PTRATIO: Hər müəllimə düşən şagird sayı artdıqca mənzil qiymətləri azalır.Bunun səbəbi, müəllim-şagird nisbətinin daha aşağı olması, hər bir şagirdə daha az diqqətin ayrılması ilə nəticələnir ki, bu da onların məktəbdəki performansını pisləşdirə bilər. Adətən bu, özəl məktəblərlə müqayisədə dövlət məktəblərindəki ssenaridir. Və dövlət məktəblərinin ətrafındakı evlərin qiymətləri ümumiyyətlə özəl məktəblərin ətrafındakı evlərdən aşağıdır.
RM: RM-nin dəyəri xətti artdıqca qiymətlər artır. Bunun səbəbi odur ki, daha çox otaq daha çox yer nəzərdə tutur və beləliklə, bütün digər amilləri sabit alaraq daha çox xərc tələb edir.
Datasetdə maraqlı fakt MEDV-nin maksimum dəyəridir. Orijinal datasetin təsvirində belə deyilir: №14 Dəyişən 50.00-da senzuraya məruz qalır (50.000 dollarlıq MEDV qiymətinə uyğundur). Buna əsasən, 50.00-dən yuxarı olan dəyərlər MEDV proqnozlaşdırmaya kömək etməyə bilər. MEDV-ın 50.00-dan yüksək kənar göstəricilərini çıxaraq.
df = boston_df[~(boston_df['MEDV'] >= 50.0)]
print(np.shape(df))(490, 14)
Log transformasiyası vasitəsilə dataların əyriliyini azaldacayıq.
y = np.log1p(y)
for col in x.columns:
if np.abs(x[col].skew()) > 0.3:
x[col] = np.log1p(x[col])Modelin qurulması və performansı (Model Building and Model performance)
Maşın Öyrənmə növünün müəyyən edilməsi:
Problemə əsasən başa düşə bilərik ki, ML Reqressiya modeli yaratmalıyıq, həm də hədəf dəyişən kəsilməzdir.
Datasetin təlim və test qruplarına bölünməsi
Bir öyrənmə alqoritmi üçün dataseti təlim və test qruplarpına bölməyin faydası nədir?
Maşın öyrənmə modelləri arasında seçim etmək üçün bir yola ehtiyacımız var. Bizim məqsədimiz nümunədən kənar datalar üzərində modelin ehtimal olunan performansını qiymətləndirməkdir. İlkin olaraq eyni data üzərində test və təlim edə bilərik. Amma təlimin dəqiqliyi artdıqca təlim datasına daha uyğun olan mürəkkəb modellər yaranır. Daha çox dəyişən əlavə etməklə dəqiqliyi 100 faizə çatdıra bilərik, lakin yaxşı ümumiləşdirmə edə bilməyəcəyik. Alternativ olaraq dataseti təlim və testdən ibarət iki hissəyə bölə bilərik. Beləliklə model iki müxtəlif data üzərində test və təlim oluna bilər.
from sklearn.model_selection import train_test_split
X= df[['LSTAT', 'PTRATIO', 'RM']]
Y= df['MEDV']
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.2, random_state=5)
print(X_train.shape)
print(X_test.shape)
print(Y_train.shape)
print(Y_test.shape)(392, 3)
(98, 3)
(392,)
(98,)
Xətti reqressiya (Linear Regression) modelinin qurulması
Modelimizi həm təlim, həm də test dataları üzərində öyrətmək üçün scikit-learn-in LinearRegression-dan istifadə edirik. Xətti reqressiya, verilmiş müstəqil dəyişən (x) əsasında asılı dəyişən dəyərinin (y) proqnozlaşdırılması tapşırığını yerinə yetirir. Beləliklə, bu reqressiya texnikası x və y arasında xətti əlaqə tapır.
Modelimizi RMSE və R2 score-metriklərindən istifadə edərək qiymətləndirəcəyik. Metrikər bir modelin nə qədər yaxşı performans göstərdiyini ölçür.
Root Mean Squared Error (RMSE): Həqiqi dəyərlə proqnozlaşdırılan dəyər arasındakı orta kök kvadrat fərqidir. MSE-nin kvadrat kökünü götürməklə, rmse alırıq.
RMSE dəyərinin mümkün qədər aşağı olmasını arzu olunandır, RMSE dəyəri nə qədər aşağı olarsa, modelin proqnozları yaxşı deməkdir. Daha yüksək RMSE, proqnozlaşdırılan və real dəyər arasında böyük sapmaların olduğunu göstərir.

n = datanın ümumi sayı
yj = real dəyər
ŷj= proqnozlaşdırılan dəyər
R squared
R kvadratı modelin dəqiqliyini müəyyən etmək üçün istifadə edilən məşhur metrikdir. Data nöqtələrinin reqressiya alqoritmi tərəfindən yaradılan uyğun xəttə nə qədər yaxın olduğunu bildirir. Daha böyük R kvadrat dəyəri daha yaxşı uyğunluğu göstərir. Müstəqil dəyişən ilə asılı dəyişən arasındakı doğru əlaqəni tapmağa kömək edir.
R² balı 0 ilə 1 arasında dəyişir. R² 1-ə nə qədər yaxın olsa, reqressiya modeli bir o qədər yaxşıdır. R² 0-a bərabərdirsə, model təsadüfi modeldən daha yaxşı performans göstərmir. R² mənfi olarsa, reqressiya modeli səhvdir.
Kvadratların cəmi ilə kvadratların ümumi cəminin nisbətidir
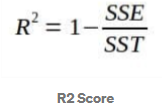
burada SSE real dəyərlə proqnozlaşdırılan dəyər arasındakı fərqin kvadratının cəmidir.
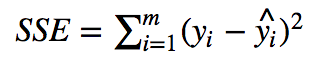
və, SST real dəyərlə, real dəyərin ədədi ortası arasındakı fərqin kvadratının ümumi cəmidir.
from sklearn.linear_model import LinearRegression
regressor_linear = LinearRegression()
regressor_linear.fit(X_train, Y_train)from sklearn.metrics import r2_score# Predicting R2 Score the Train set results
y_pred_linear_train = regressor_linear.predict(X_train)
r2_score_linear_train = r2_score(Y_train, y_pred_linear_train)# Predicting R2 Score the Test set results
y_pred_linear_test = regressor_linear.predict(X_test)
r2_score_linear_test = r2_score(Y_test, y_pred_linear_test)# Predicting RMSE the Test set results
rmse_linear = (np.sqrt(mean_squared_error(Y_test, y_pred_linear_test)))
print('train R2_score : ', r2_score_linear_train)
print('test R2_score: ', r2_score_linear_test)
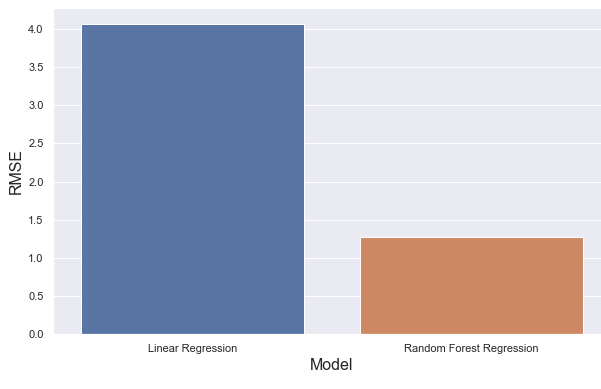
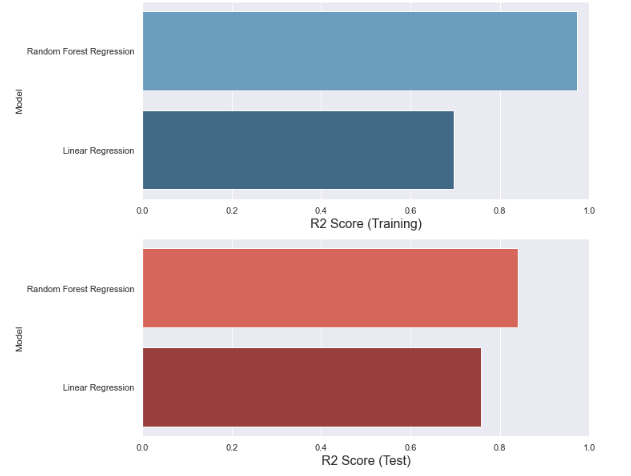
print("RMSE: ", rmse_linear)train R2_score : 0.6972731138467182
test R2_score: 0.7570955510695241
RMSE: 4.067751559941674
Məsələn, verilmiş modeldə R-kvadrat dəyəri 0,69-dur, bu o deməkdir ki, qiymətdəki ümumi fərqin təxminən 69%-i cari reqressiya modeli ilə müəyyən edilə bilər.
Random Forest Modelinin qurulması.
Digər seçdiyimiz maşın öyrənmə modeli Random Forest Reqressiya Modelidir və bunun səbəbi:
- Random Forest Regression reqressiya üçün ansambl öyrənmə metodundan istifadə edən supervised öyrənmə alqoritmidir. Ansambl öyrənmə metodu tək modeldən daha dəqiq proqnoz vermək üçün çoxlu maşın öyrənmə alqoritmlərindən gələn proqnozları birləşdirən bir texnikadır.
- Random Forest modelləri datalarımızda mövcud olan kənar göstəricilərə qarşı dayanıqlıdır və normallaşdırıldıqdan sonra daha yaxşı performans göstərən digər maşın öyrənmə modellərindən fərqli olaraq statistik problemləri tamamilə görməməzlikdən gəlir.
- Random Forests modelləri minimal data hazırlığı tələb edir. Miqyaslama (scaling) və ya normallaşdırma tələb etmədən kateqorik, ədədi və ikili dəyişənlər asanlıqla proqnazlaşdıra bilər.
from sklearn.ensemble import RandomForestRegressor
regressor_rf = RandomForestRegressor(n_estimators = 500, random_state = 0)
regressor_rf.fit(X_train, Y_train.ravel())# Predicting R2 Score the Train set results
y_pred_rf_train = regressor_rf.predict(X_train)
r2_score_rf_train = r2_score(Y_train, y_pred_rf_train)
print('rmse train test result: ', rmse_rf)# Predicting R2 Score the Test set results
y_pred_rf_test = regressor_rf.predict(X_test)
r2_score_rf_test = r2_score(Y_test, y_pred_rf_test)
print("RMSE: ", rmse_rf)rmse_rf = (np.sqrt(mean_squared_error(Y_test, y_pred_rf_test)))
rmse_rf = (np.sqrt(mean_squared_error(Y_train, y_pred_rf_train)))
print('R2_score (train): ', r2_score_rf_train)
print('R2_score (test): ', r2_score_rf_test)RMSE: 1.2682482533569068
R2_score (train): 0.9732486208596913
R2_score (test): 0.840230615775178
Proqnoz və Yekun Hesab
models = [('Linear Regression', rmse_linear, r2_score_linear_train, r2_score_linear_test),
('Random Forest Regression', rmse_rf, r2_score_rf_train, r2_score_rf_test)]predict = pd.DataFrame(data = models, columns=['Model', 'RMSE', 'R2_Score(training)', 'R2_Score(test)'])
predict

Random Forest modelinin daha yüksək nəticəsi vardır. Burada Linear regression modeli üçün test nəticəsi dəqiqliyi təlim nəticəsi dəqiqliyindən daha yüksəkdir. Bu isə normal deyildir. Test dəqiqliyi təlimdən yüksək olmamalıdır, çünki model təlim üçün optimallaşdırılmışdır. Model underfitting-dir.
predict.sort_values(by=['RMSE'], ascending=False, inplace=True)f, axe = plt.subplots(1,1, figsize=(10,6))
sns.barplot(x='Model', y='RMSE', data=predict, ax = axe)
axe.set_xlabel('Model', size=16)
axe.set_ylabel('RMSE', size=16)plt.show()
f, axes = plt.subplots(2,1, figsize=(10,10))predict.sort_values(by=['R2_Score(training)'], ascending=False, inplace=True)sns.barplot(x='R2_Score(training)', y='Model', data = predict, palette='Blues_d', ax = axes[0])axes[0].set_xlabel('R2 Score (Training)', size=16)
axes[0].set_ylabel('Model')
axes[0].set_xlim(0,1.0)predict.sort_values(by=['R2_Score(test)'], ascending=False, inplace=True)sns.barplot(x='R2_Score(test)', y='Model', data = predict, palette='Reds_d', ax = axes[1])axes[1].set_xlabel('R2 Score (Test)', size=16)
axes[1].set_ylabel('Model')
axes[1].set_xlim(0,1.0)plt.show()
Bir neçə cümlə ilə qurulmuş modelin real dünya şəraitində istifadə edilməli olub-olmadığını müzakirə edək. Bildiyimiz kimi data 1978-ci ildə toplanmışdır və bugünku gün öz aktuallığını itirmiş hesab edilə bilər. 1978-ci ildən bəri demoqrafik göstəricilər çox dəyişmişdir. Proqnozlaşdırıcı olaraq istifadə edilən dəyişənlərdən əlavə olaraq cinayət nisbətləri, şəhərə yaxınlıq, ictimai nəqliyyata giriş və daha çox dəyişən əlavə edilə bilər.
